Medium RSS Feed:
- KeyForge: The Tower Defense Game That Taught Me to Actually Use Vim (And Why That Matters More Than…
- Can You Actually Prove AI ROI in Software Engineering?
- Really, Just don´t Introduce State in the Appplication
- The Line of Rust That “Broke the Internet”
- Why Your ML Platform Will Fail at 3 AM (And How Netflix, Uber, and Airbnb Built Theirs to Never Go…
- Building a Distributed Job Scheduler That Won’t Melt Down at 3 AM: A Deep Dive from Bad to…
- Your Documentation is Technically Perfect and Nobody Reads It
- AI Agents & Software Engineering: New Patterns or Old Tricks?
- Know the Basics: Software Architecture and Coding in the Age of AI
- Why I Built VoiceBridge: Taking Back Control of My Voice Workflow
- The Global Search Problem Nobody Talks About (And How I Finally Solved It)
- Why Uploading to S3 Isn’t Enough: The Evolution of Large File Transfer Architecture
- The Engineering Manager Revolution: How AI, Remote Work, and Decentralized Leadership Are Reshaping…
- SaaS Security Wakeup Call: The Industry’s $81 Billion Reality Check This Week
- The Observability Revolution: AI, OpenTelemetry, and Cost Optimization Drive This Week’s Major…
- Software Architecture in 2025: Where AI Meets Event-Driven Reality
- Distributed Systems Revolution: How AI Infrastructure and Edge Computing Are Reshaping Enterprise…
- Cloud Computing in 2025: AI Surge Drives $723 Billion Market Revolution
- AI Image Generation Enters New Golden Age as Competition Heats Up and Technology Breakthroughs…
- The AI Power Grab: How August 2025 Became the Month Everything Changed
- Forget ATS Hacks — Build Signals Recruiters Can’t Fake
- Decomposing the Monolith Starts With Facing the Mess
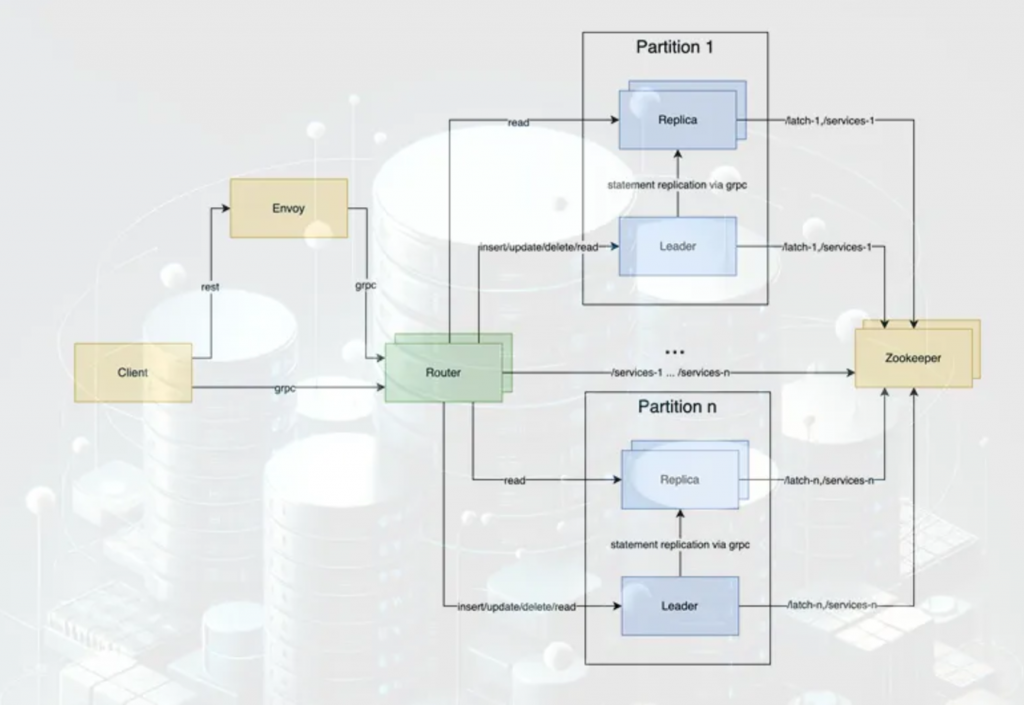
- You Thought Replication Was Just a Database Thing? Think Again
- Talk Smart, Rise Fast: The Harsh Truth About Tech Careers
- The Debugger in Your Mind: How Positivity Fixes More Than Code
- From Dot-Com to Dot-Bot: Is AI the Biggest Gold Rush Yet?
- Why Playing on Easy Mode Makes You a Worse Engineer
- Building a Custom Database System from Scratch
- API Gone Wild: What Happens When You Don’t Plan for Scale
- Modern Error Handling Is Losing the Plot — Here’s How to Bring It Back
Selected Articles:
Database Concepts Simplified
In the ever-evolving landscape of software engineering, I’ve journeyed through a myriad of concepts, but one domain has consistently captivated me: distributed systems. My exploration has spanned from delving into seminal works like Google’s Bigtable and Amazon’s DynamoDB, to immersing myself in the profound insights of Martin Kleppmann’s ‘Designing Data-Intensive Applications.’ Each step in this voyage has not only struck me with awe but also intricately woven together to craft a comprehensive understanding of practical software architecture.
Theory, though enlightening, yearns for application to truly breathe life into its intricate concepts. This realization sparked in me an ambitious endeavor: to architect my own database. Such a feat, especially in the realm of distributed databases, is a Herculean task, perhaps demanding a five-year odyssey of unwavering dedication. Time, however, is a luxury I can ill-afford.
Thus was born a new vision: to create and chronicle the development of a simplified distributed key-value store. This isn’t just another blog post; it’s an odyssey segmented into an article series, mirroring the rich, chaptered tapestry of ‘Designing Data-Intensive Applications.’
Building High-Performance Teams
I thrive on jumping from one team to the next, tackling new challenges, and watching freshly formed groups evolve into powerhouses of productivity. What’s my secret? The ability to walk away, knowing they’ll keep delivering at lightning speed without needing me anymore. Over the years, I’ve honed a few principles to make this happen, and I’m sharing them here. Spoiler: It’s not magic — it’s method.


Don’t build a Distributed System if you don’t understand these Issues
The year is 2024, and the digital realm is akin to the Wild West, where every coder is a gunslinger and every system a potential showdown. We’re in an era where the words “distributed systems” evoke both awe and dread, a landscape dotted with microservices, databases, and event-driven architectures like frontier towns on a vast, uncharted map. Each day, I saddle up and ride through this decentralized terrain, leading a convoy that includes message queues, homegrown microservices, alliances with other teams, and dealings with mysterious third-party services.
My journey through the pages of “Designing Data-Intensive Applications” was akin to acquiring a map to hidden treasures and perilous pitfalls. With this grimoire in hand, I’ve become a cautious navigator, aware that in the unyielding expanse of network communications, what can go wrong, will indeed find a moment to plunge into chaos. This revelation hit me like a thunderbolt in a clear sky — I realized that our creations, our digital offspring, were flawed, subtly misaligned with the unforgiving laws of this frontier.
These contraptions, these marvels of our making, function with a deceiving smoothness, betraying us only in fleeting, critical moments. The tragedy is not in their failure, but in their audacity to falter just when we’ve grown too confident in their reliability. Thus, armed with my tales of caution and enlightenment, I invite you to delve into the heart of this tempestuous world. Together, let’s uncover the secrets that lurk within, so you may tread these paths with the wisdom of forewarning, steering clear of the pitfalls that once ensnared me.
Everyone loves to talk about Architecture, few mean Code Architecture
Lately, it seems like everyone either wants to be an architect or already claims the title. This trend spans multiple domains. For instance, in the world of data, a data architect obsesses over governance and data lineage. Then there’s the Customer Success Architect, tasked with ensuring that clients meet their objectives using a company’s products or services.
In the realm of software, a software architect determines the requirements necessary for building an application and devises the best strategies for implementation. Got a system that’s heavy on reading data? Toss in a cache. Dealing with a high volume of writes? It might be time to deploy a message broker alongside a NoSQL database like Cassandra.
However, when it comes to putting these architectural plans into action, things can get a bit wild. The journey often begins with the struggles of writing unit tests, wading through the complexity of implemented requirements, and culminates in wrestling with tricky issues like cache invalidation or the notorious dual-write problem.
So, let’s inject some clarity into how we structure our code to make it future-proof. Our goal? To create a system that welcomes new team members with ease, stands the test of time, and fortifies itself against bugs. Ideally, our code should resemble a symphony — a seamless flow where chaos is banished and every component excels at its task, much like the components in the Linux paradigm.

The Hidden Complexity of Distributed State Machines
Building a distributed state machine seems straightforward at first — a concept that feels almost too simple to get wrong. But the moment you dive into implementation, the cracks begin to show. It’s a challenge I wrestle with often, and each new edge case exposes just how fragile state transitions can be in the unpredictable world of distributed systems.
Imagine this: you’re managing a resource in a relational database — an order, a ticket, or maybe a cloud service. Its lifecycle feels familiar: states like creating, updating, or deleting define its journey. These transitions are kicked off synchronously by user actions, then quietly handed over to asynchronous processes for completion. Sounds elegant, right?
But here’s the kicker — beneath this seemingly tidy flow lies a web of hidden complexity. Timing issues, lost updates, and conflicting state transitions are lurking, just waiting to cause chaos. And when they do, they’ll test your architecture — and your patience — in ways you never expected. So, how do you navigate this minefield? Let’s unpack the problem and explore the solution.
Streamlining LLMs with a GenAI Gateway
Since the release of ChatGPT 3.5 in late 2022, Generative AI has taken the tech world by storm, capturing the imagination of developers and businesses alike. The rapid growth of this field has led to the emergence of powerful tools like LangChain, which simplifies development, and Langfuse, which enhances observability. But as exciting as these advancements are, they also bring new challenges, especially for those of us looking to build applications that leverage multiple large language models (LLMs).
As a software engineer, I’ve always been intrigued by the concept of API gateways — centralized entry points that manage and streamline the complexities of working with multiple APIs, including authentication, authorization, rate limiting, and protocol conversion. But when it comes to the rapidly evolving world of Generative AI, the need for a specialized API gateway becomes even more critical.
In this article, I’ll take you through my journey of creating an API gateway tailored specifically for Generative AI. I’ll share my insights on why existing solutions from big players like Azure, AWS, and Kong didn’t quite fit the bill for my needs, and how my commitment to open-source principles led me to develop a new, more flexible gateway (link to the GitHub repository). Along the way, I’ll dive into the technical challenges I faced, the features I prioritized, and how this new project could benefit anyone looking to integrate multiple LLMs into their applications.


How to Make Faster CI/CD Pipelines
Since developer experience will suffer on slow ones.
I once checked some pipelines that took about 15–20 minutes just for running tests, checking code quality, scanning for vulnerabilities, and creating and sharing a software container (docker image). We usually use GitOps and Kubernetes for deploying our apps, so we either follow FluxCD’s image policies or update the git repository directly with the pipeline.
I’ve built similar pipelines before, and it was frustrating how slow they were. I kept wondering if there wasn’t a better way.
So, I researched more to find ways to improve. Now, my pipelines only take 3–4 minutes. Let me share how I did it.
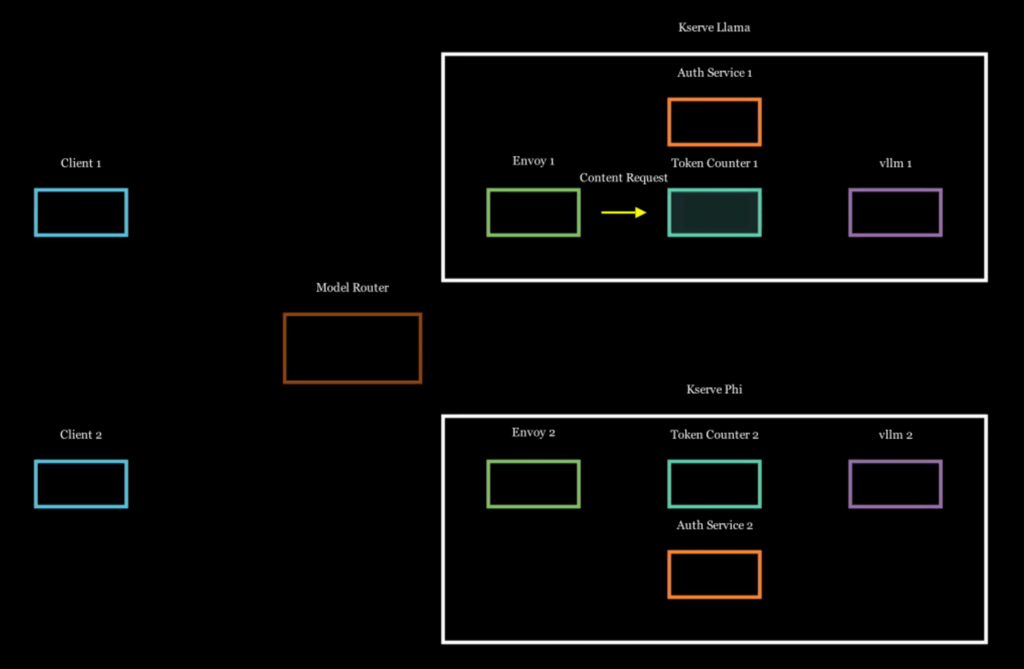
Unveiling the Magic: Scaling Large Language Models to Serve Millions
Imagine walking into a massive library where every book can converse with you, answer your questions, and even tell stories on demand. This library needs to serve millions of visitors simultaneously, each requesting different books at different times. How does the library manage this colossal task without making you wait hours for a response? Hosting large language models (LLMs) for millions of users is a similarly herculean endeavor.
Recently, I ventured into the topic to provide open-source LLMs like Llama 3 and Phi on scale like AWS Bedrock. I’m here to pull back the curtain and share insights on how you, too, can build and scale these models.

Interview: So, how do you do a transaction in a NoSQL Database
I’ve always enjoyed conducting technical interviews, especially when it comes to challenging candidates with questions that require them to think critically about core engineering concepts. One of my favorite ways to kick off these conversations is by diving into problems that mirror real-world scenarios we face in backend development — problems that involve databases, message queues, and distributed systems. My goal isn’t just to quiz candidates, but to engage them in a discussion, just like we would in the day-to-day work of an engineering team.
Here’s a scenario I often present to candidates:
Imagine we’re working within a large, distributed system. We frequently exchange messages, both asynchronously and synchronously, and sometimes we need to write data to a database while simultaneously publishing a message to a queue. How would you design a mechanism to ensure that both the write and the publish happen reliably?
The conversation usually steers towards the dual-write problem, a common issue when dealing with multiple external systems. It’s important for candidates to grasp that simply writing to the database and then publishing to the queue isn’t enough. What happens if the database write succeeds, but the queue publish fails? Or, worse yet, what if an attempt to roll back the transaction also fails? You’re left with an inconsistent state across your systems, which can lead to bigger issues down the road.